Running a computer vision model is an expensive operation. You have invested a lot of resources and time building your model. Now it turns out keeping the lights on might be even more costly. And then you realise this will cost a lot of energy as well.
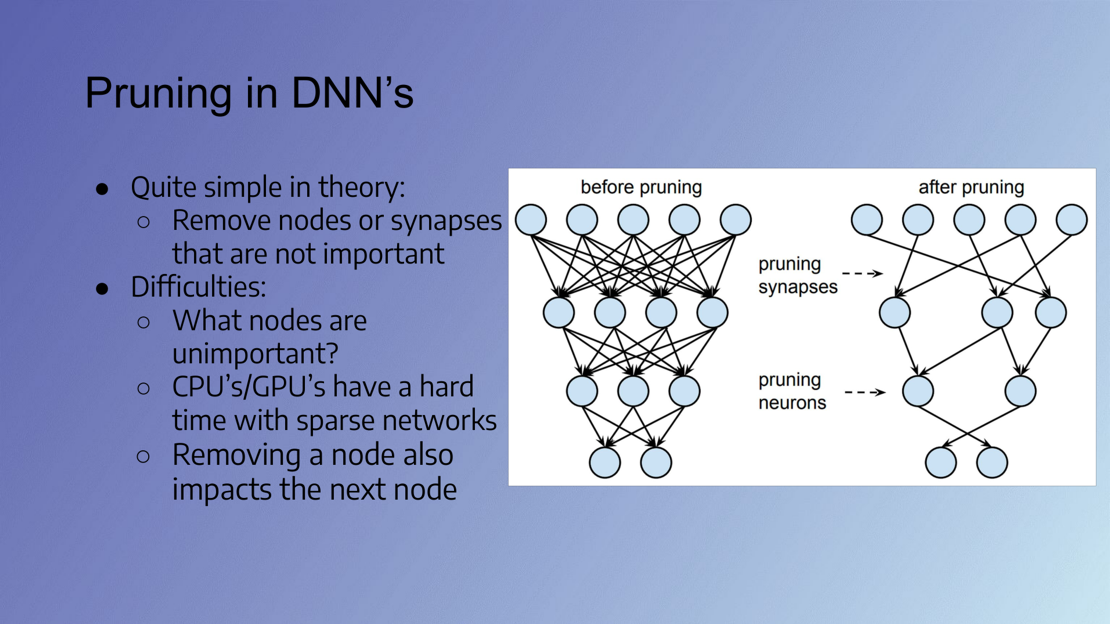
During this talk Steven van Blijderveen will explain Convolutional Neural Networks (CNN) and different types of compression methods available for CNNs, such as quantization and pruning. Quantization refers to the process of reducing the number of bits that represent a number. In the context of neural networks, this means using lower-precision formats to represent weights and activations, which can lead to significant reductions in model size. Pruning is a compression technique that involves eliminating unnecessary connections or weights in a neural network. For example, if we imagine a neural network as a vast web of interconnected neurons, pruning can be likened to trimming off the less important connections, allowing the network to focus on the more significant ones.
Besides explaining about these types of compression, Steven will also talk about knowledge distillation, which is a technique where a compact neural network, known as the student, is trained to imitate a larger, more complex network or ensemble of networks, known as the teacher. The student network learns from the output of the teacher network rather than the raw data, enabling it to achieve comparable performance with a fraction of the resources.
Matthijs Plat will explain about the solution that AIminify has built for the high energy consumption and how this can be used in the world of AI.
Date
27 March 2024, 11:00-12:00 CET
Venue
ITC Langezijds Building, Room LA 2211
Hallenweg 8, 7522 NH Enschede
Speaker
Steven van Blijderveen
Steven van Blijderveen is Artificial Intelligence Engineer at AIminify. After getting his Artificial Intelligence master's in Utrecht he started working for Tinify, the world leader in image compression. In this role he developed an upscaler, which makes it possible to resize images into bigger formats with minimal loss of quality. He did this by improving upon an existing GAN, a type of generative neural network. After that he investigated heavily in different techniques of neural network compression and the fully automated pipeline to get this up and running. This results in AIminify which offers an on-premise optimization solution with zero configuration. Aiminify is able to compress PyTorch as well as Tensorflow models, without any settings. This will increase the speed of use and deployability with minimal loss of quality.
Matthijs Plat
Matthijs Plat is the founder of AIminify. After his BIT study at the University of Twente Matthijs has been working in manufacturing for 15 years. In 2018 he started his own business and as of 2019 he is running Tinify, the world leader in image compression. In 2023 the decision was made to start investing in neural network compression, which resulted in AIminify.
Video
This video player uses cookies
Questions and Answers
The main application area of AIminify seems to be in edge computing with constrained hardware. I tried this two years ago and used TensorFlow and TensorFlow Lite to reduce the CNN with mainly quantization, accuracy loss was minimal. What has improved in this, is there anything new? What is AIminify doing differently than for example TensorFlow Lite quantization? We wanted to quantize and prune our own models for Tinyfy. What we found is that if we look online, there are a lot of tools you can use to reduce the size and increase the speed of the neural network but everything is quite complicated, you need probably a few days to really read up on what parameters to use, how does everything work and what this will do to the network. What we wanted is something that you can just say, put in your network into this part of the code and then it detects everything automatically and just makes the correct choices for you. So that’s the edge AIminify has over other libraries.
And concerning what's happened in the recent years, obviously because AI is growing in hyper speed, also a lot is happening in the compression world. I think in terms of quantization, the most interesting thing is that especially for large language models, like ChatGPT and Lama, they are now doing 4-bit quantization, even 2-bit quantization! They quantize to only two bits and still the network is working. You can see that if you go from 32 bits to 2 bits, that's a huge size reduction. This is really interesting and I'm curious to see how small they can go.
This answers my question.
Thank you for your feedback
Could you provide more information on how to use AIminify? When we started with a AIminify we had Tinify in the background, and with Tinify you can just upload your image, we compress it and give it back to you. So, when we started to talk to people, we asked, "Give us your model and then we will compress it and give it back to you". And everybody said that's a secret of the company! Although there were some exceptions, most of them were like "You're not going to touch our model". So, we needed to find a solution for that. We now have an on-premise solution. We run the compression and use your training data on your infrastructure. So please do try it and give us your feedback, because every time we run it somewhere we get some more new information. If something is not working, we need to setup an extra setting and this way we broaden our scope of what kind of models we can handle. So that's also very helpful for us.
This answers my question.
Thank you for your feedback
As in TinyPNG, when you upload an image it lets you know the expected size after compression. So in the case of AIminify, what kind of information is provided beforehand about the optimized model? No, in the case of AIminify, it is super dependent on network, and we also haven't used it enough on a lot of different neural networks to be confident in what we estimate yet. For the quantization it is easy, because we know beforehand if it saves ~50 or ~75% storage. But for the latency improvement, that comes from the pruning, and can differ from 10x speed increase to 2x speed increase. Fow now, hard to tell why sometimes the speed increases more than other times. This is something we are currently investigating.
This answers my question.
Thank you for your feedback
Have you tried AIminify compression on open-source models? We have tried it on smaller models like VGG and we've seen ~75% size decrease and 3x to 4x latency improvement. On those it works pretty well. We tried lot of open source models to at least be sure that that we can handle those. However, when people used these models, they may need to tweak it a little, or add extra layers and do something to run in their own environments. In such cases the AI tries to prune layers that shouldn't be pruned. So, whenever we get a new model, at least for now, we need to look at it and see if is there anything that we haven't seen before and assess how should we handle that.
This answers my question.
Thank you for your feedback
As you are a commercial company, how is presenting to academia interesting to you? If all of you start using it and give us new feedback on your case studies about what works and doesn't work, it will help us speed up the improvement of the product. The more the product is used, the more answers we have.
This answers my question.
Thank you for your feedback
You rightfully emphasised that the hardware has an effect. How about having different versions of the models compressed to targets with different capabilities which the system can automatically select? We're trying to keep the number of parameters that the user can use as low as possible, because we don't want to complicate it where the user has to put a lot of parameters in and doesn't really understand what it's doing. But we do want to put some easy stuff in there like, "What kind of CPU are you using? What kind of GPU?". Just for the algorithm to be sure to optimize it in the correct way. For some companies, we already noticed that they for example run their known networks on both CPUs and GPUs depending on their customers. So, we want to optimize in a way that they can run multiple different versions of their network at the same time on different hardware.
This answers my question.
Thank you for your feedback
Is the Student-Teacher way of training prone to overfitting? That depends a bit on how good your teacher model is. You hope that your Teacher model is already good enough that the Student model just wants to impersonate. So yeah, you do overfit on your teacher model, but that's kind of what you want to do. You just want to make a smaller model that has outputs similar to your teacher model. If your Teacher model has some errors in it, then probably your Student model is also going to have those errors. It's not as much an improvement. It's just an improvement in size and speed.
This answers my question.
Thank you for your feedback
We see that we can improve the speed and performance, but nowadays we also look at energy consumption. Have you studied the impact of compression on energy consumption, or will you be interested in doing something like that? I think we would be interested in that. For now, the obvious thing is that if the network does speed up, then there is less GPU hours to use, which saves a lot of energy. We've been talking to people building CPUs, they don't seem much interested in it as then they sell less hardware. However, in the GPU world, it's kind of different because it's more money intense. They are more interested in compressing, also for their end users. I think in five years from now, this will be more seriously considered in the industry.
This answers my question.
Thank you for your feedback