Greetings from the Big Geodata Newsletter!
In this issue you will find information on GenCast that predicts weather conditions with state-of-the-art accuracy, VirtualiZarr to create virtual Zarr stores using xarray syntax, SLURM-style job arrays on the Cloud with Coiled, TorchSpatial - a python package for spatial representation learning and geo-aware model development, and Population Dynamics Foundation Model by Google Research.
Happy reading!
You can access the previous issues of the newsletter on our web portal. If you find the newsletter useful, please share the subscription link below with your network.
GenCast predicts weather conditions with state-of-the-art accuracy
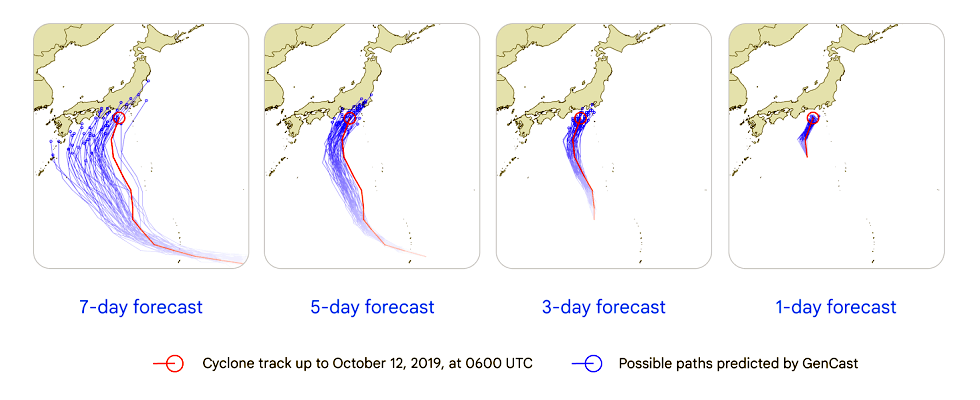
Image credits: Google Deepmind, 2024
GenCast is an advanced AI model developed by Google DeepMind that enhances weather forecasting by predicting uncertainties and risks with high accuracy. Unlike traditional deterministic models, GenCast employs an ensemble approach, generating over 50 possible weather scenarios to provide a comprehensive outlook up to 15 days ahead. Trained on four decades of historical data from the European Centre for Medium-Range Weather Forecasts (ECMWF), GenCast has demonstrated superior performance, outperforming ECMWF's ENS system in 97.2% of evaluated targets. Its ability to predict extreme weather events, such as heatwaves, cold spells, and high winds, as well as tropical cyclone tracks, enables timely and cost-effective preventive actions. GenCast is also efficient, generating a 15-day forecast in just eight minutes using a single Google Cloud TPU v5, compared to the hours required by traditional physics-based models on supercomputers. This efficiency, combined with its advanced predictive capabilities, positions GenCast as a significant advancement in the field of AI-based weather prediction.
Explore the full potential of GenCast in advancing weather forecasting here or check out the paper published here. The code implementing GenCast is available along with links to ERA5 dataset and the model weights.
VirtualiZarr: Create Virtual Zarr Stores Using Xarray Syntax
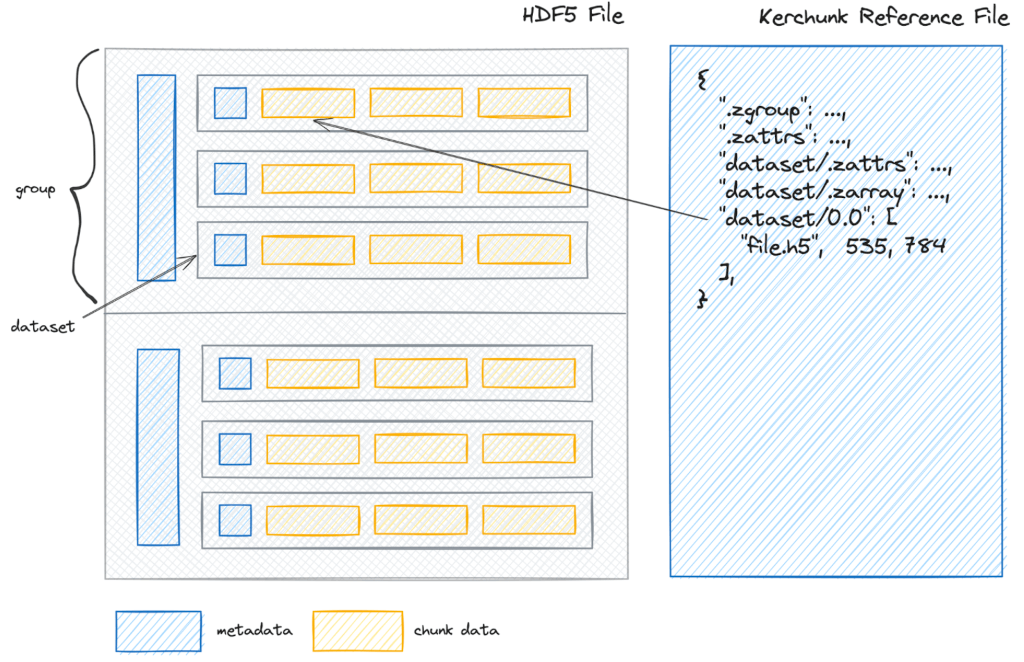
Image credits: AGU, 2024
VirtualiZarr is a tool designed for creating virtual Zarr stores, enabling cloud-optimized access to legacy file formats like NetCDF without requiring data duplication. This approach meets the growing demand for accessing archival datasets using modern cloud-friendly patterns. VirtualiZarr works by generating metadata-only representations of legacy datasets. It uses “chunk manifests” to represent data at the array level, referencing byte ranges in the original files in Kerchunk reference file format. Unlike Kerchunk, VirtualiZarr supports writing these virtual arrays as valid Zarr stores, making Zarr a "universal reader" for archival data across various file formats. In comparison to Kerchunk, which focuses on creating fsspec reference files to simplify access to cloud-native formats like NetCDF or HDF5, VirtualiZarr emphasizes direct visualization of Zarr data. This makes it more suitable for tasks involving interactive data exploration.
Learn more about VirtualiZarr’s capabilities here, and explore its documentation here.
SLURM-Style Job Arrays on the Cloud with Coiled
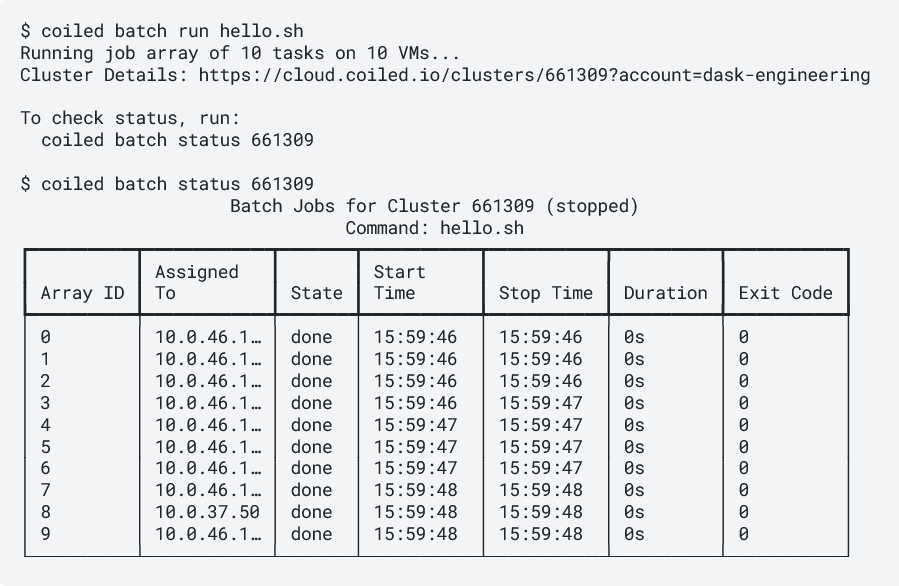
Image credits: Coiled, 2024
Coiled now offers SLURM-style job arrays, making cloud-based parallel computing more accessible. This feature allows users to run multiple instances of a script across virtual machines (VMs) in the cloud, providing a straightforward way to manage workflows requiring parallel processing. With simple #COILED directives, users can specify the number of parallel tasks and the computational resources needed. For example, adding #COILED ntasks 10 to a script automatically runs ten parallel tasks across separate VMs. The system manages resource provisioning, software deployment, task execution, and cleanup, reducing the complexity of managing cloud resources manually. Coiled’s approach supports customization, allowing users to set specific memory allocations and container environments for each task. Monitoring and debugging tools also provide task statuses and logs for easier management.
Learn more about how Coiled’s SLURM-style job arrays enable efficient cloud-based parallel processing here.
TorchSpatial: Spatial Representation Learning and Geo-Aware Model Development
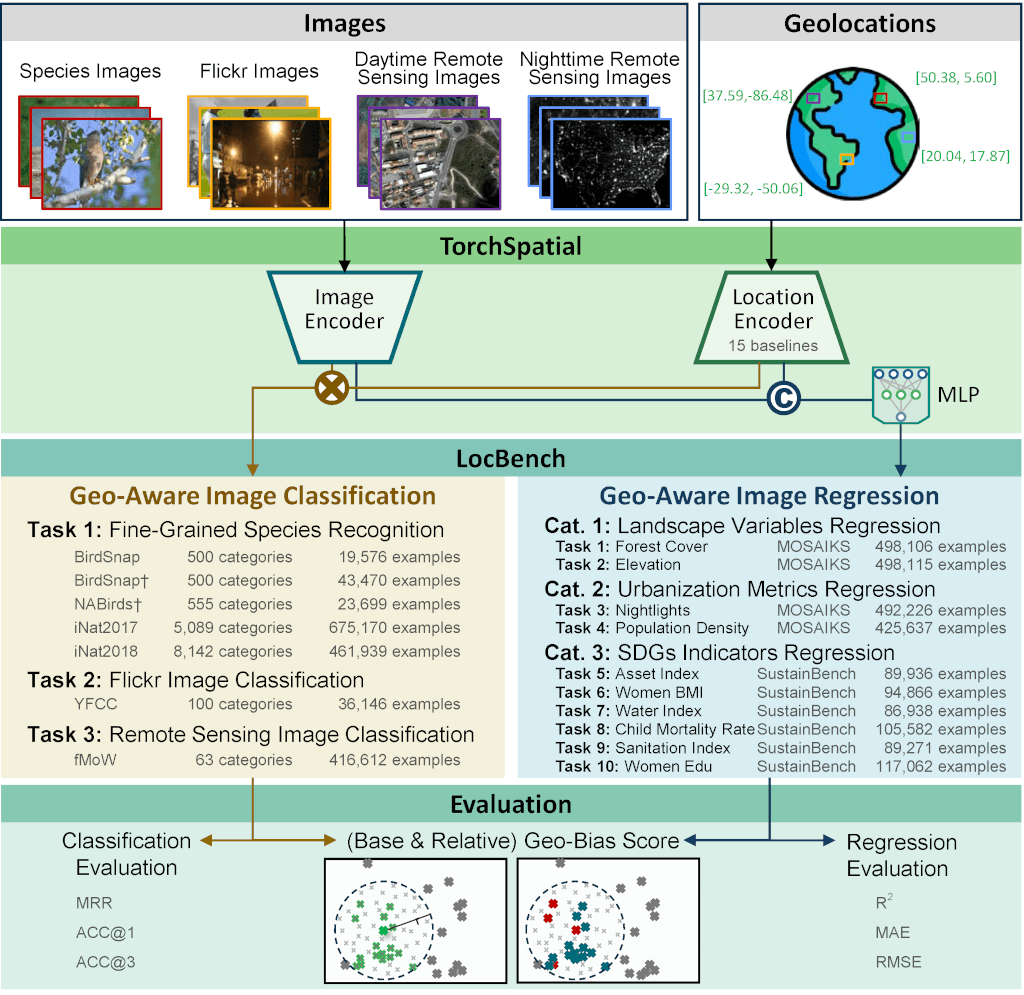
Image credits: TorchSpatial, 2024
TorchSpatial is a Python package that simplifies spatial representation learning (SRL) by providing tools to encode spatial data and develop geo-aware models. It addresses the challenges of SRL by offering a scalable and reproducible framework that supports various spatial tasks, such as species recognition, satellite image classification, and socioeconomic analysis. TorchSpatial includes 15 widely used location encoders designed for both 2D and 3D data, such as Space2Vec and Sphere2Vec, along with pre-trained model checkpoints for seamless implementation. The package also integrates with popular image encoders, like MoCo-V2+TP, and provides workflows for geo-aware image classification and regression tasks. Users can leverage 17 datasets, including BirdSnap, Population Density, and Nightlight Luminosity, for tasks ranging from land-use classification to predicting socioeconomic indicators. By automating data preprocessing and offering reusable components, TorchSpatial supports rapid experimentation and development of GeoAI models. Future updates aim to expand its capabilities to handle more complex spatial data types like polygons and polylines.
Explore TorchSpatial's capabilities and learn how it supports geospatial research here. Discover its applications in GeoAI tasks and workflows here.
Upcoming Meetings
- Introduction to Supercomputing, Part I
Amsterdam Science Park, 16 January - GPU Computing in Python using PyCUDA
Amsterdam Science Park, 23 January - Introduction to Deep Learning
Netherlands eScience Center, Amsterdam, 28-29 January 2025 - Introduction to Deep Learning
Amsterdam Science Park, 30 January - EGU25 General Assembly
Vienna, Austria, 27 April - 2 May 2025 (Call for abstracts, until 15 January) - CNG Conference 2025
Utah, USA, 30 April – 2 May 2025

The "Big" Picture
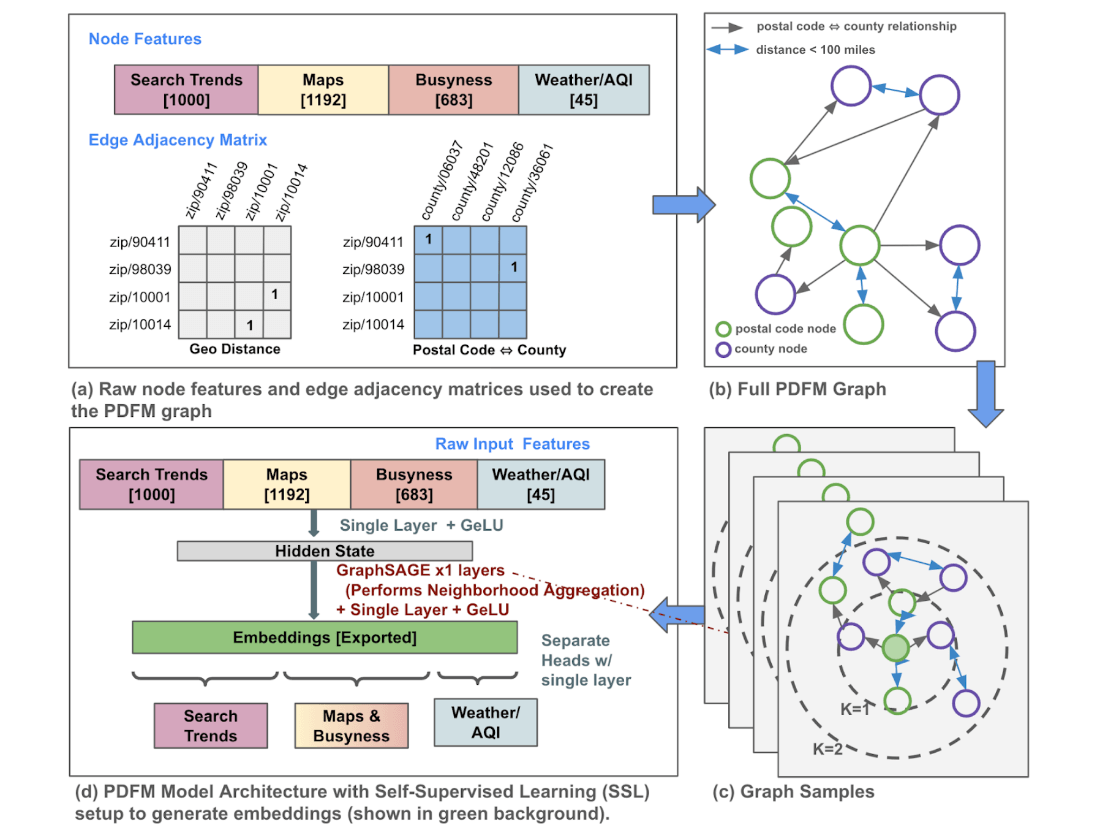 Image credits: Agarwal et al., 2024
Image credits: Agarwal et al., 2024
Google Research has unveiled the Population Dynamics Foundation Model (PDFM), a new tool designed to enhance geospatial inference by integrating diverse datasets through advanced machine learning techniques. At the core of PDFM is a graph neural network (GNN) that processes data from various sources, including human behavior indicators (such as maps, business metrics, and aggregated search trends) and environmental factors (like weather and air quality). This data is structured into a graph with nodes representing U.S. counties and postal codes, capturing spatial relationships through proximity-based connections. PDFM has been benchmarked across 27 geospatial tasks, demonstrating superior performance in health, socio-economic, and environmental domains compared to traditional methods and models like SatCLIP and GeoCLIP. Its adaptability to various data resolutions makes it suitable for tasks such as interpolation, extrapolation, super-resolution, and forecasting. This initiative aligns with Google's commitment to advancing AI for societal benefit, complementing other projects like the Open Health Stack and the TimesFM time-series foundation model.
A blog post is available here and for extended reading, try the article. Explore the Population Dynamics Foundation Model and access the resources like data and code here.
Agarwal, M., Sun, M., Kamath, C., Muslim, A., Sarker, P., Paul, J., Yee, H., Sieniek, M., Jablonski, K., Mayer, Y., Fork, D., Sheila, D. G., McPike, J., Boulanger, A., Shekel, T., Schottlander, D., Xiao, Y., Manukonda, M. C., Liu, Y., . . . Prasad, G. (2024). General Geospatial Inference with a Population Dynamics Foundation Model. https://arxiv.org/abs/2411.07207