Greetings from the Big Geodata Newsletter!
In this issue you will find information on utilizing GDAL with AWS EMR-Serverless, GridMesa: an adaptive grid approximation model to handle large spatial data, and on creating EO data cubes with Cubo and XEE.
After more than 3 years of operation and 500,000+ multi-core CPU hours provided for academic work, we are happy to invite you our first Geospatial Computing Platform Users Meeting on 12 June, 2024 to share experience, exchange your ideas, and voice needs! Find more information about it below and sign-up early to participate.
Dr. Rosa Aguilar, Dr. Ellen-Wien Augustin and Prof. Dr. Raul Zurita-Milla from the Department of Geo-Information Processing at ITC share their experience in using our Geospatial Computing Platform to model pollen and pollen allergies in the Netherlands. Don't miss their Big Geodata Story!
Happy reading!
You can access the previous issues of the newsletter on our web portal. If you find the newsletter useful, please share the subscription link below with your network.
Using GDAL with EMR-serverless for large-scale geodata processing
Image credits: AWS, 2024
The data processing landscape has undergone a dramatic transformation, marking a departure from the era of supercomputers to a new age of scalability and accessibility through cloud computing. Initially constrained by expensive hardware, innovations like MapReduce paved the way for distributed computing. Apache Spark further accelerated this progress by capitalizing on the expanding availability of RAM. AWS's EMR was considered as a game-changer by many, streamlining the deployment of large-scale data workloads. Despite its benefits, deploying EMR requires expertise and resource management. Enter EMR-Serverless, a paradigm shift eliminating these hurdles. With custom execution environments and automated scaling, it heralds a future where cutting-edge technologies are both accessible and economically feasible, revolutionizing data processing as we know it.
Read more on utilizing Geospatial Data Abstraction Library (GDAL) with AWS EMR-Serverless for extensive data processing that involves leveraging the power of GDAL within the context of AWS EMR-Serverless for handling massive datasets efficiently.
Creating EO Data Cubes with ease!
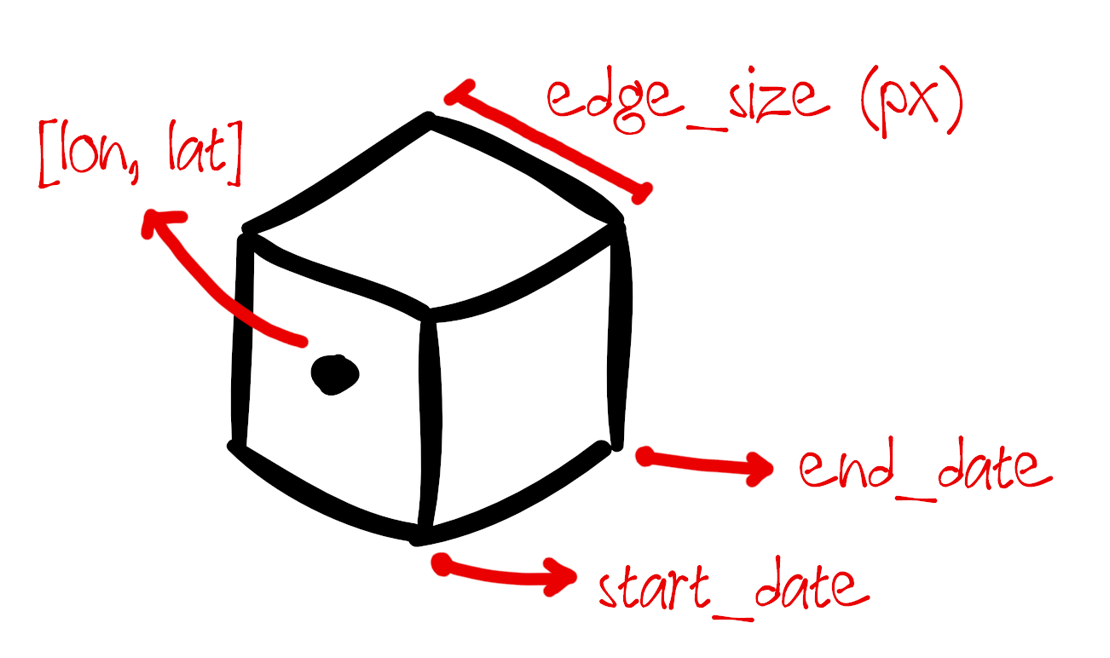 Image credits: Cubo, 2024
Image credits: Cubo, 2024
The SpatioTemporal Asset Catalog (STAC) specifications provide standardized format to describe geospatial datasets. This format is adopted by many data providers to expose data to clients in a consistent manner. Users can access any data hosted in this format from different satellite missions, instruments, or collections with simply using the STAC API. Cubo is a python package that lets users of STAC easily create Earth System Data Cubes (ESDCs) for analysis on long term data. The cubo.create() function requires minimal inputs such as start/end date, edge size and central pixel location to create an Xarray object of the specified STAC data collection. The function also allows users to specify the resolution in meters for the ESDC. This cube as an xarray object can easily be used for further analysis tasks, including deep learning.
The documentation of the package provides interesting examples to use cubo. The package can also be used to access datasets from the Google Earth Engine catalogue, where the dataset is retrieved via XEE. Read more about it below!
XEE: Using Xarray with Google Earth Engine
 Image credits: Medium, 2024
Image credits: Medium, 2024
With over 90+ petabytes of analysis-ready data in the GEE catalogue, the platform has launched a few new tools for easier processing of geospatial workflows. XEE is a new python tool that integrates Google Earth Engine (GEE) with Xarray, a popular open-source python package for processing large multidimensional arrays. XEE allows users to work on Earth Engine ImageCollections as Xarray Datasets. This is especially helpful when processing large spatiotemporal EO or climate datasets as the xarray integration uses Dask under the hood for computing across multiple processors. The package also allows users to export data into the cloud optimised Zarr format. However as with the limitations of GEE, using the XEE tool for large datasets requires users to have a GEE account with a high volume endpoint.
An article by Ali Ahmadalipour gives insight into using XEE for processing large climate data. GEE also recently introduced new data extraction methods that allow users to export data programmatically in a variety of formats.
Upcoming Meetings
- CRIB Training Workshop: Introduction to Docker
13 March, Enschede - Training Workshop: Image Processing with Python
11-13 March, Online - Training Workshop: Parallel Programming with Python
19-20 March, Online
- Training Workshop: Intermediate Research Software Development with Python
15-17 April, Online - EGU 2024
14-19 April 2024, Vienna, Austria
- Training Workshop: Machine Learning in Python with scikit-learn
22-25 April, Online - GeoAI and Earth Observation Advances and Future Trends
Special Issue, Submission deadline: 30 April 2024 - Geospatial World Forum
13-16 May 2024, Rotterdam, Netherlands - Geospatial Computing Platform Users Meeting
12 June 2024, ITC

Recent Releases
- Pandas: Software library for data manipulation and analysis
2.2.1 (23/02/2024) - albumentations: Fast image augmentation library
1.4.0 (17/02/2024) - cuGraph: RAPIDS Graph Analytics Library for GPUs
2024.02.00 (13/02/2024) - PDAL: Point Data Abstraction Library
2.6.3 (06/02/2024)
The "Big" Picture
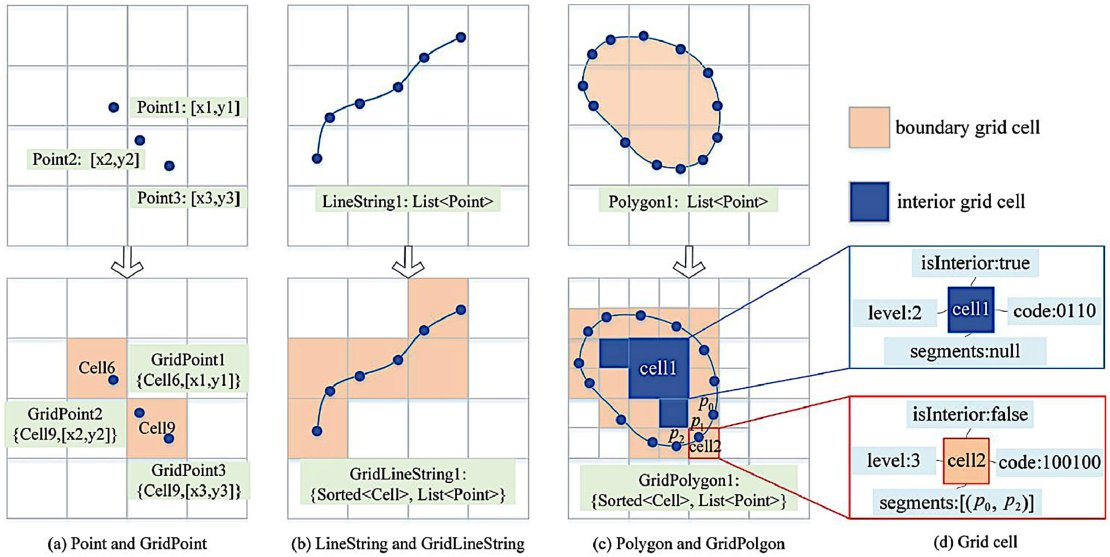 Image credits: Yang et al., 2024
Image credits: Yang et al., 2024
In response to the pressing need for managing vast spatial data sets, numerous spatial data management systems have emerged, often built on distributed NoSQL databases. However, existing systems typically use coarse Minimum Bounding Rectangles (MBRs) to approximate spatial objects, leading to inefficiencies in spatial operations and retrieval processes due to mismatches and varied index levels. GridMesa, a new grid-based management system designed to handle massive spatial data more effectively addresses these challenges. It features an adaptive grid-based approximation model called Grid-AM, which optimizes spatial computations by balancing filtering and refinement costs. Additionally, GridMesa utilizes a NoSQL-based storage scheme integrated with HBase, incorporating a novel secondary index to enhance query window quality. With efficient query algorithms supporting various data retrieval tasks, such as range and kNN queries, GridMesa demonstrates superior performance compared to popular NoSQL-based systems like GeoMesa and GeoWave, as evidenced by extensive experiments conducted with real-world datasets.
Yang, X., Guan, X., Pang, Z., Kui, X., and Wu, H. (2024). GridMesa: A NoSQL-based big spatial data management system with an adaptive grid approximation model. Future Generation Computer Systems, 155, 324–339. doi:10.1016/j.future.2024.02.010