Greetings from the Big Geodata Newsletter!
In this issue you will find information on XDGGS for planetary-scale data cube computations with Discrete Global Grid Systems, Arkouda for large-scale geocomputing by using Pangeo stack, DMR++ for easy access to HDF4/5 data on the Cloud without reformatting, accelerated data analytics workflows with RAPIDS cuDF, and Vector Data Cubes for geospatial insights with spatiotemporal vector data.
During our recent Big Geodata Talk, Dr. Leandro Parente from OpenGeoHub shared their experience in moving global time-series predictions involving EO data from modeling to production within the Open-Earth-Monitor and Global Pasture Watch projects. You can watch the talk and access the slides here.
Happy reading!
You can access the previous issues of the newsletter on our web portal. If you find the newsletter useful, please share the subscription link below with your network.
XDGGS: A community-driven library to support planetary DGGS data cube computations

Image credits: XDGGS, 2024
The open-source library XDGGS is a new tool designed to support planetary-scale data cube computations using Discrete Global Grid Systems (DGGSs). DGGS divides the Earth's surface into hierarchical, grid-based cells with unique identifiers, enabling efficient spatial data management and analysis. Unlike traditional map projections, DGGS minimizes distortions at a global level, which are particularly important for planetary studies. However, implementing DGGS for practical use often involves complex workflows and varying standards across different libraries. XDGGS addresses this gap by providing a unified and user-friendly framework to simplify these complexities. As an extension of the xarray library, XDGGS simplifies workflows such as spatial indexing, data aggregation, and multi-resolution analysis. It integrates seamlessly with existing DGGS frameworks like H3, HEALPix, and rHEALPix. This interoperability allows users to convert, visualize, and analyze large geospatial datasets effectively.
To help users get started, the XDGGS GitHub repository provides tutorials, example notebooks, and documentation. For deeper insights into DGGS principles, the OGC DGGS Specification and a recent study detail their benefits and applications.
Arkouda brings scalable performance to Pangeo
Image credits: Lubomir Franko, 2024 and Arkouda, 2024
{kind=link}
{kind=link}
Arkouda offers a practical alternative to Dask for large-scale data analysis, especially for Pangeo datasets. Both tools feature Pythonic interfaces, but they differ in scalability and execution models. Dask is effective for distributed workflows and integrates well into Python ecosystems. However, its dynamic task scheduling can add overhead, limiting efficiency with very large datasets. Arkouda overcomes this with parallel computation and an eager evaluation strategy, executing operations immediately and reducing scheduling overhead. Built on the Chapel programming language, it uses opaque array chunking to abstract complexity and a server-based execution model to minimize data movement, enhancing performance at scale. Another key distinction lies in how the two frameworks handle arrays. Dask arrays extend NumPy functionality to distributed data, allowing operations on datasets that exceed the memory of a single machine. In contrast, Arkouda focuses on distributed arrays optimized specifically for large-scale computations. Arkouda arrays leverage the parallelism of underlying hardware to perform operations on distributed data without requiring it to fit in memory.
For more interesting insights, watch a demo for the Xarray backend server from the Pangeo showcase and explore Arkouda to learn how it simplifies large-scale dataset analysis.
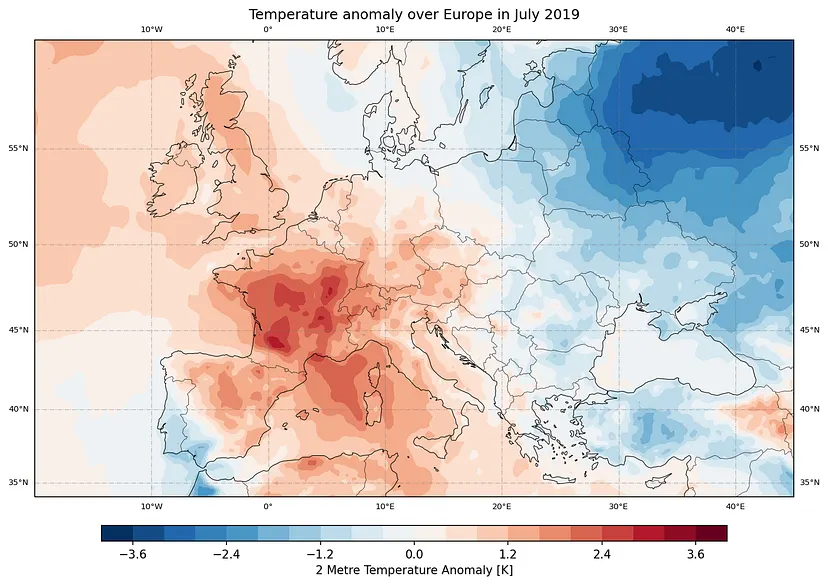
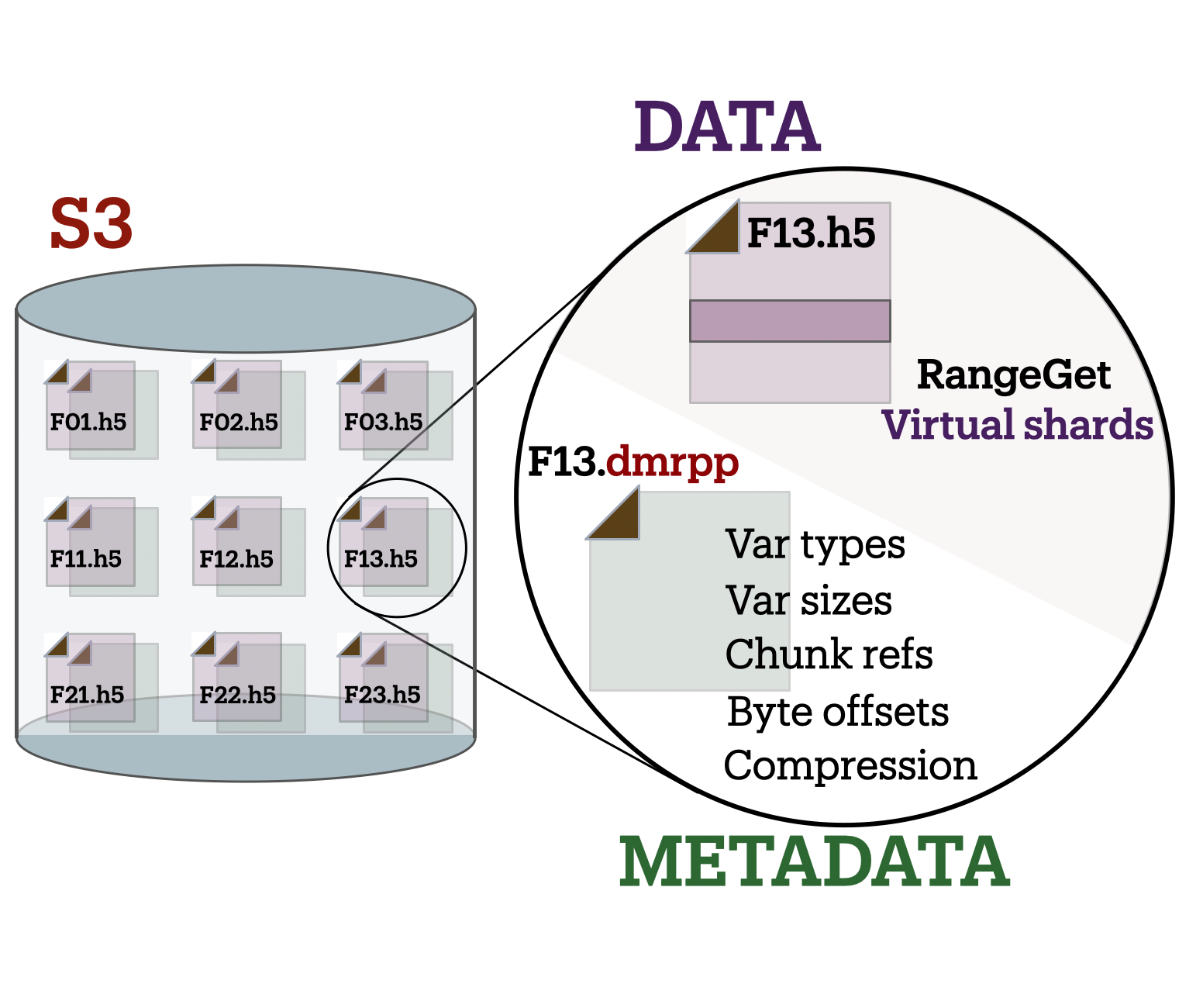
Efficient access to Earth data with DMR++
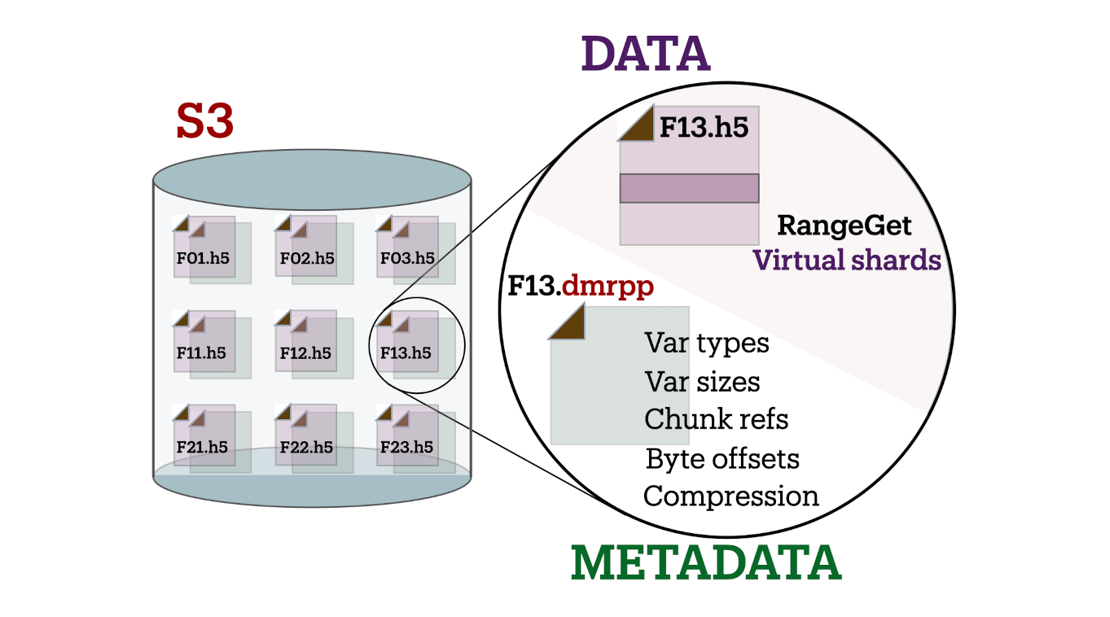
Image credits: OpenDAP, 2024
{kind=link}
DMR++ offers a streamlined approach for accessing Earth science datasets stored in HDF4 and HDF5 formats on cloud platforms like Amazon S3, Google Cloud, and Azure. Using XML-based metadata, it facilitates efficient subsetting and retrieval of data without reformatting, making it well-suited for modern cloud computing workflows. Its optimization techniques, such as aggregating smaller data chunks, improve performance while maintaining compatibility with archival data structures. Moreover, DMR++ typically outperforms cloud-optimized versions of HDF5. The integration of sidecar files addresses challenges like missing georeferencing or computed data, enhancing usability for applications in satellite imagery and atmospheric studies. By bridging the gap between older formats and cloud environments, DMR++ enables scalable access to decades of archival data.
Discover more about DMR++ and its role in Earth data workflows at the AGU 2024 Fall Meeting here.
Accelerating data processing with RAPIDS cuDF and Unified Memory
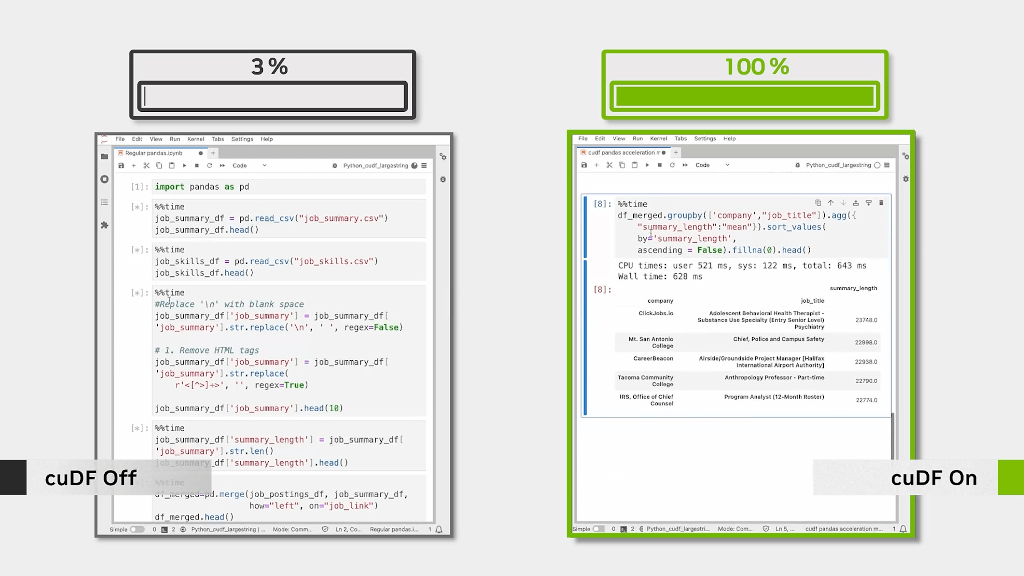
Image credits: NVIDIA, 2024
RAPIDS cuDF, a GPU-accelerated DataFrame library, offers a powerful alternative to Pandas for large-scale data processing. Designed for NVIDIA GPUs, cuDF enables seamless data manipulation with familiar pandas-like syntax while delivering up to 30x performance gains for large datasets. One of its standout features is Unified Memory, which automatically manages data transfer between CPU and GPU memory. This innovation allows cuDF to handle datasets larger than GPU memory, eliminating manual memory management. For those already using pandas, the transition to cuDF is straightforward, thanks to its intuitive API and tight integration with the broader RAPIDS ecosystem. Combining cuDF with tools like cuML (machine learning) and cuGraph (graph analytics) allows for efficient, end-to-end workflows fully on GPUs.
Explore how RAPIDS cuDF can optimize your data workflows on their official page here.
Upcoming Meetings
- Introduction to Deep Learning
Netherlands eScience Center, Amsterdam, 28-29 January 2025 - Introduction to Supercomputing, Part I
SURF, Online, 4 February 2025 - EGU25 General Assembly
Vienna, Austria, 27 April - 2 May 2025 (Call for abstracts, until 15 January) - CNG Conference 2025
Utah, USA, 30 April – 2 May 2025

The "Big" Picture
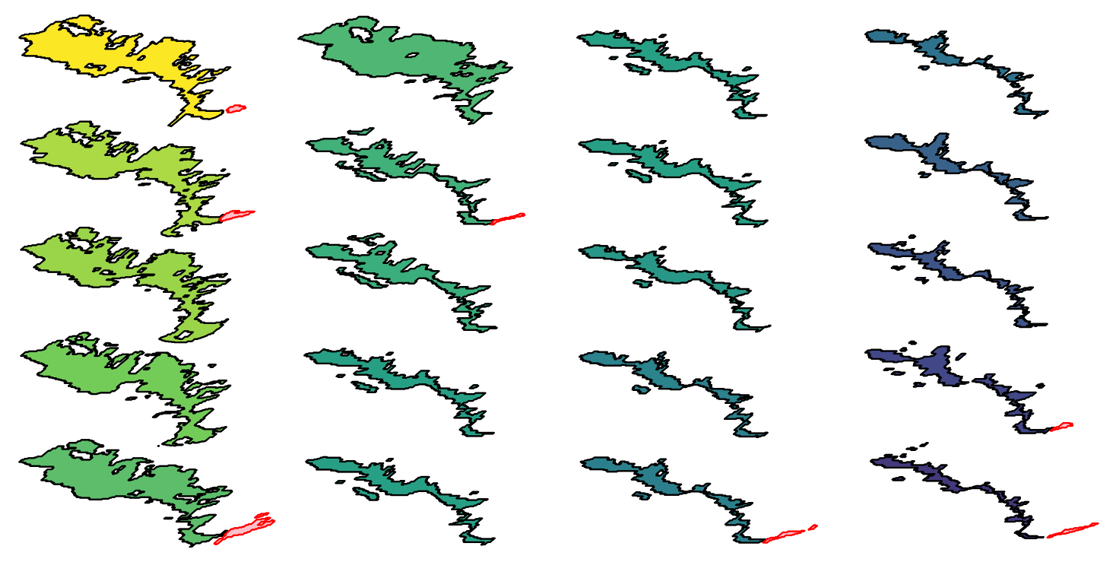 Image credits: Abad et al., 2024
Image credits: Abad et al., 2024
By accommodating changes in feature size and shape, vector data cubes provide an advanced way to track and analyze dynamic landscapes efficiently that evolve over time and space. There are two main formats for implementation: array-based cubes, which facilitate spatial computations across time, and tabular cubes, designed to streamline relational space-time data analysis. These formats enable tasks like filtering, aggregating, and visualizing data to monitor phenomena such as lava flows, landslides, and other geomorphological processes. For instance, the Fagradalsfjall lava flow in Iceland and the Butangbunasi landslide in Taiwan demonstrate how these frameworks provide insights into landform changes over decades. Tools like the R packages stars and cubble are driving the adoption of vector data cubes, offering robust solutions for spatial and temporal analysis while ensuring compatibility with raster data cubes.
Unlock the potential of vector data cubes for tracking dynamic landscapes here. Explore advanced tools like stars and cubble to enhance your geospatial workflows.
Abad, L., Sudmanns, M., and Hölbling, D. (2024) Vector data cubes for features evolving in space and time, AGILE GIScience Ser., 5, 16, doi:10.5194/agile-giss-5-16-2024.