Greetings from the Big Geodata Newsletter!
In this issue you will find information on a new method to visualise in-memory raster data using Leafmap, the Google-Microsoft combined buildings footprints dataset, cloud-optimised Geo-Zarr format, and a state-of-the-art global high-resolution canopy height model.
Sharad Shingade, an alumnus of ITC, recently shared his experience of using our Geospatial Computing Platform for mapping and measurement of the quality of urban expansion. Don't miss his Big Geodata Story!
We also have an upcoming training workshop in February - Introduction to Geospatial Raster and Vector Data with Python. Find more information about it below and sign-up early to participate!
Happy reading!
You can access the previous issues of the newsletter on our web portal. If you find the newsletter useful, please share the subscription link below with your network.
Leafmap Now Supports In-memory Rasters
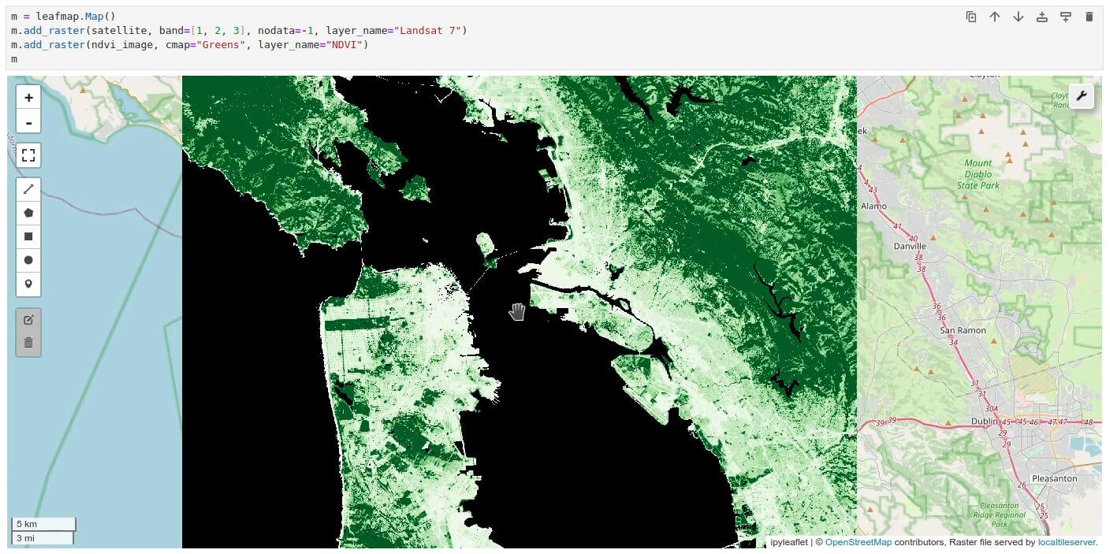 Image credits: Leafmap, 2024
Image credits: Leafmap, 2024
We recently talked about Lonboard, a Python library for fast GPU-based interactive visualization of large vector data. Leafmap is another such Python package for geospatial analysis and interactive visualization of both vector and raster data in a Jupyter environment. Built on open-source packages such as folium, ipyleaflet, ipywidgets and WhiteboxTools, it lets users to view data on an interactive GUI with 500+ tools to carry out advanced geospatial analysis with very minimal code. An exciting development in the leafmap project is the introduction of in-memory raster data visualization. Conventionally, we process raster data using arrays in numpy or xarray and then save the results to visualize it. Leafmap now allows users to convert intermediate processing arrays into in-memory rasterio objects that can be instantaneously mapped. This is especially helpful when working with large datasets, cutting down on time and memory required to save each raster. Users can test intermediate results on interactive maps and save only the final results.
Dr. Qiusheng Wu, author of the project gives some example use cases of this new feature in a tutorial. To learn more about leafmap, check out the leafmap documentation website.
OGC Forms GeoZarr Standards Working Group
 Image credits: Christophe Noël, 2023
Image credits: Christophe Noël, 2023
GeoZarr, a product of the Zarr community project, is an innovative solution that addresses challenges posed by large geospatial datasets, offering improved performance in cloud-based geocomputing workflows. Zarr's chunked storage library supports parallel reads and writes, integrating seamlessly with diverse storage systems. Unlike HDF5, Zarr allows for thread-based parallelism, compression in parallel writes, and native cloud support. GeoZarr intersects data engineering and geospatial computing needs, and provides an effective solution for handling the increasing volume of geodata on the Cloud, making large-scale data analysis more accessible. GeoZarr's alignment with the Spatiotemporal Asset Catalog (STAC) facilitates its role as a data catalog, enhancing findability and complementing other cloud-optimized formats.
The Open Geospatial Consortium (OGC) recently formed the OGC GeoZarr Standards Working Group. The working group aims to develop a GeoZarr standard that establishes flexible and inclusive conventions that meets the diverse requirements of the geospatial domain. You can read more here about the working group and join its activities.
A Single Dataset for 2.5 Billion Building Footprints
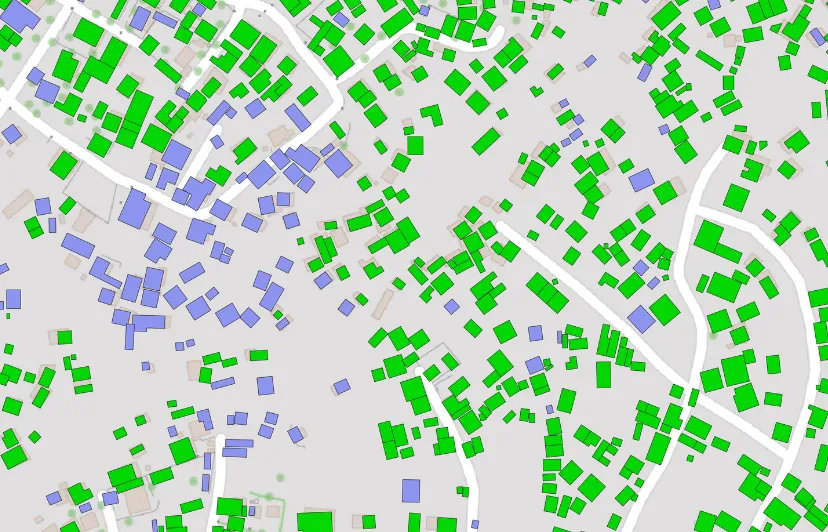
Image credits: Darell van der Voort, 2023
A total of 2.5 billion building footprints are available in one dataset through a comprehensive integration of the latest versions of Google's Open Buildings and Microsoft's Building Footprints. VIDA made this endeavour possible by harnessing the power of BigQuery. Thanks to BigQuery's massive distributed computing capabilities, they could merge the majority of footprints in under just 30 seconds. The comprehensive dataset, which stands as one of the most extensive openly accessible datasets available, features geometries, area measurements (in meters), confidence metrics (exclusive to Google footprints), and the source of each footprint. Users can conveniently access the data in cloud-native geospatial formats, including GeoParquet, FlatGeobuf, and PMTiles.
You can use the Source Cooperative to browse and access data in a cloud-native manner. Check it out!
Upcoming Meetings
- Training Workshop: Introduction to Geospatial Raster and Vector Data with Python
14-15 February, Enschede, Netherlands - Training Workshop: Good Practices in Research Software Development
26-29 February, Online - Training Workshop: Parallel Programming with Python
19-20 March, Online - EGU 2024
14-19 April 2024, Vienna, Austria - GeoAI and Earth Observation Advances and Future Trends
Special Issue, Submission deadline: 30 April 2024 - Geospatial World Forum
13-16 May 2024, Rotterdam, Netherlands - Big Geospatial Data Hackathon with Open Infrastructure and Tools (GEO-OPEN-HACK 2024)
24-28 June 2024, Laxenburg, Austria

Recent Releases
- PyTorch: Machine learning framework based on the Torch library
2.2.0 (30/01/2024) - Keras: High-level neural networks API
3.0.4 (20/01/2024) - scikit-learn: Machine learning library for Python
1.4.0 (19/01/2024) - Apache Sedona: Cluster computing framework for large-scale geospatial data
1.5.1 (18/01/2024)
The "Big" Picture
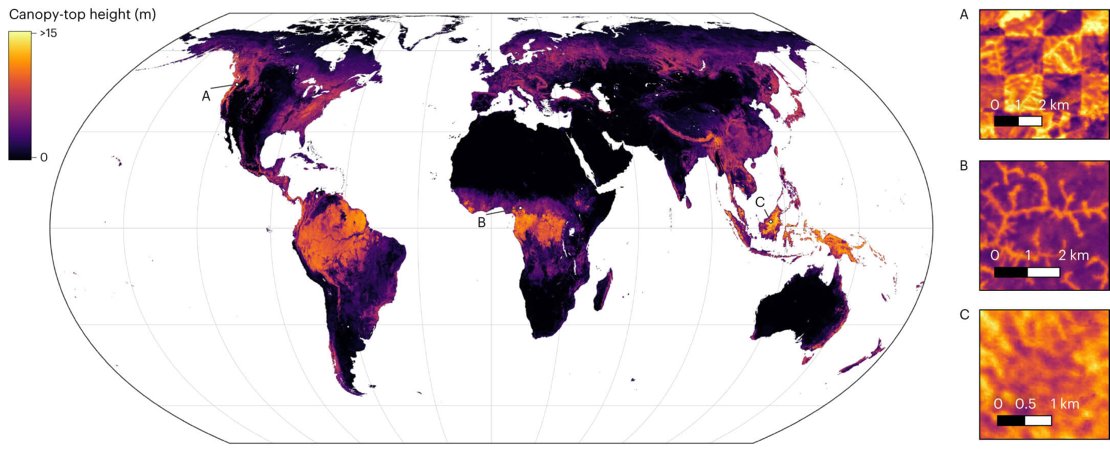
Image credits: Lang et al., 2023
A new global high-resolution canopy height model reveals that only 5% of the global landmass is covered by trees taller than 30m and only 34% of that is located within protected forest areas. Researchers have developed this fine-grained 10 m resolution map by fusing sparse canopy height data from the Global Ecosystem Dynamics Investigation (GEDI, a space-borne LiDAR mission) with dense optical satellite images from Sentinel-2. The dataset was developed using a probabilistic sparsely supervised deep learning model approach with an ensemble of convolutional neural networks that determines the canopy height using temporal as well as textural information from the optical imagery. To ensure the usability of the dataset for decision makers, the model also quantifies the predictive uncertainty at each pixel based on both the data ambiguity, and the uncertainty of model parameters.
Using 600 million samples of Sentinel-2 image patches around every GEDI footprint, the 160 TB dataset was parallelly processed on a high-performance cluster, taking ~27,000 GPU hours (3 years!) in computation time and ten days in real time! Explore the interactive global dataset on this link.
Lang, N., Jetz, W., Schindler, K., and Wegner, J. D. (2023) A high-resolution canopy height model of the Earth. Nature Ecology & Evolution, 7:1778–1789. doi:10.1038/s41559-023-02206-6.